Padding Oracle Attack实例分析
2010-10-09 00:20 by 老赵, 12030 visits在之前的《浅谈》一文中,我提到《Automated Padding Oracle Attacks with PadBuster》一文对理解Padding Oracle Attack非常有帮助,并打算将其翻译出来。现在我便来实现承诺了。《Automated》一文其实是在介绍PadBuster这个自动攻击工具,不过其中也通过实例加配图详细介绍了Padding Oracle Attack的原理——这也是我会翻译的部分。这篇文章写的非常通俗易懂,您只需要了解一点点关于加密的基础概念即可,不需要对加密算法或其证明有任何了解。我想只要配合些许Wikipedia上的定义,大部分朋友应该都能顺利地理解这篇文章。
以下为翻译内容。
最近出现了许多有关Padding Oracle Attack的声音,在今年夏天早些时候的BlakHat Europe会议上,Juliano Rizzo和Thai Duong在他们的演讲中演示了这种攻击方式。虽然Padding Oracle是种相对容易的攻击方式,但如果您还没有对它的自动攻击原理有一定了解,那么利用它进行攻击还是需要不少时间的。由于缺少好用的工具以识别及利用Padding Oracles,我们开发了一个基于Padding Oracle的内部脚本,PadBuster,现在我们打算将它与社区分享。您可以在这里下载工具,现在我们也会花些时间来讨论这个工具的工作方式,以及它所支持的几种场景。
一些背景知识
在讨论PadBuster之前,我们先来简单讨论一下典型的Padding Oracle Attack基础。故名思义,Padding Oracle Attack背后的关键性概念便是加/解密时的填充(Padding)。明文信息可以是任意长度,但是块状加密算法需要所有的信息都由一定数量的数据块组成。为了满足这样的需求,便需要对明文进行填充,这样便可以将它分割为完整的数据块。
加密时可以使用多种填充规则,但最常见的填充方式之一是在PKCS#5标准中定义的规则。PCKS#5的填充方式为:明文的最后一个数据块包含N个字节的填充数据(N取决于明文最后一块的数据长度)。下图是一些示例,展示了不同长度的单词(FIG、BANANA、AVOCADO、PLANTAIN、PASSIONFRUIT)以及它们使用PKCS#5填充后的结果(每个数据块为8字节长)。
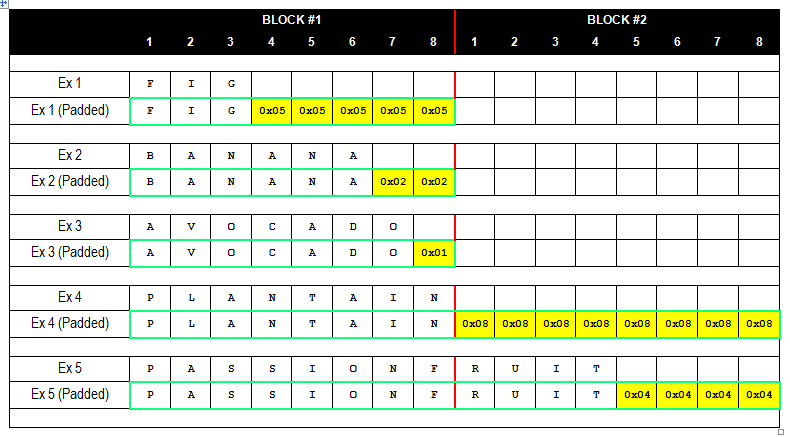
请注意,每个字符串都至少有1个字节的填充数据,因此7字节的值(如AVOCADO)则使用0x01进行填充,而8字节的值(如PLANTAIN)则会填充一个额外的数据块。填充字节的值也说明了填充的字节数,因此待加密数据的最后几个字节必须是以下几种情况之一:
- 一个0x01(0x01)
- 两个0x02(0x02,0x02)
- 三个0x03(0x03,0x03,0x03)
- 四个0x04(0x04,0x04,0x04,0x04)
- ……
如果解密后的最后一个数据块末尾并非这些合法的字节序列,大部分加/解密程序都会抛出一个填充异常。这个异常对于攻击者尤为关键,它是Padding Oracle Attack的基础。
一个基本的Padding Oracle Attack场景
作为一个具体例子,请考虑以下场景:
某个应用程序使用Query String参数来传递一个用户加密后的用户名,公司ID及角色ID。参数使用CBC模式加密,每次都使用不同的初始化向量(IV,Initialization Vector)并添加在密文前段。
当应用程序接受到加密后的值以后,它将返回三种情况:
- 接受到正确的密文之后(填充正确且包含合法的值),应用程序正常返回(200 - OK)。
- 接受到非法的密文之后(解密后发现填充不正确),应用程序抛出一个解密异常(500 - Internal Server Error)。
- 接受到合法的密文(填充正确)但解密后得到一个非法的值,应用程序显示自定义错误消息(200 - OK)。
上述的场景体现了一个典型的Padding Oracle(填充提示),我们可以利用应用程序的行为轻易了解某个加密的值是否填充正确。这里的单词Oracle代表了一种机制,用于了解某个测试是否通过。
既然已经给出了场景,那么我们便来查看应用程序所使用的一个加密后的参数。这个参数保存了使用分号隔离的一系列值,在我们的示例中,则是用户名(BRIAN),公司ID(12)及角色ID(12):因此这里的明文是“BRIAN;12;2;”。以下则是经过加密的Query String实例,请注意加密后的UID参数使用了ASCII十六进制表示法。
http://sampleapp/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6
在实际情况中,攻击者并不会知道这里所对应的明文是多少,不过作为示例,我们已经知道了明文、填充、以及加密后的值(如下表)。正如之前所提到的那样,IV添加在密文的前段,即最前面8个字节。

攻击者可以根据加密后值的长度来推测出数据块的大小。由于长度(这里是24)能被8整除但不能被16整除,因此可以得知数据块的大小是8个字节。现在我们来观察下加密和解密的内部实现,下图便展示了字节级别的运算方式,这对以后攻击方式的讨论很有帮助。请注意,其中带圆圈的加号表示XOR(异或)操作。
加密过程:
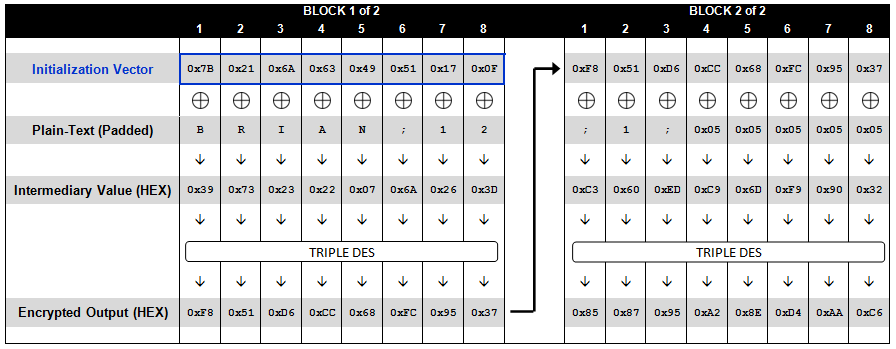
解密过程:

同样值得指出的是,解密之后的最后一个数据块,其结尾应该包含正确的填充序列。如果这点没有满足,那么加/解密程序就会抛出一个填充异常。
利用Padding Oracle进行解密
我们现在来关注一下如何利用Padding Oracle Attack进行解密。我们将每次操作一个单独的加密块,因此我们可以独立出第一块密文(IV后的那块),在前面加上全为NULL的IV值,并发送至应用程序。以下是URL极其相关回复:
Request: http://sampleapp/home.jsp?UID=0000000000000000F851D6CC68FC9537 Response: 500 - Internal Server Error
回复的500错误是意料之中的,因为这个值在解密后完全非法。下图展示了应用程序在尝试解密的时候究竟做了哪些事情。您会发现,因为我们只处理单个数据块,因此它的结尾必须包含正确的填充字节,才能避免出现非法填充异常。

如上图所示,在解密之后,数据块的末尾并没有包含正确的填充序列,因此出现了异常。现在我们将IV加一,并发送同样的密文,看看会发生什么:
Request: http://sampleapp/home.jsp?UID=0000000000000001F851D6CC68FC9537 Response: 500 - Internal Server Error
与之前一样,我们得到了500异常。这是因为在解密后我们还是没有获得合法的填充序列。稍有不同的是,我们在深入内部之后会发现,最后一个字节的值会有所变化(变成了0x3C而不是0x3D)。
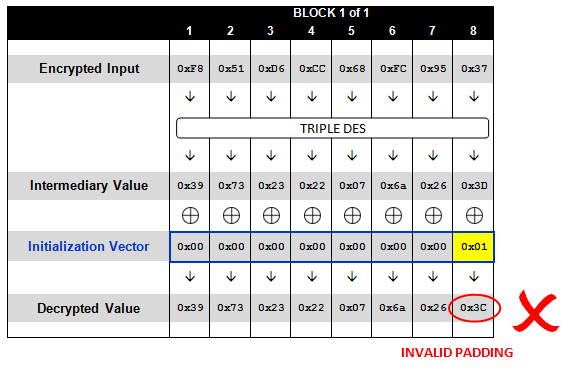
如果我们重复发送这样的请求,每次将IV的最后一个字节加一(直至0xFF),那么最终我们将会产生一个合法的单字节填充序列(0x01)。对于可能的256个值中,只有一个值会产生正确的填充字节0x01。遇上这个值的时候,你应该得到一个不同于其他255个请求的回复结果:
Request: http://sampleapp/home.jsp?UID=000000000000003CF851D6CC68FC9537 Response: 200 OK
同样,我们从示意图中了解一下此时发生了什么:
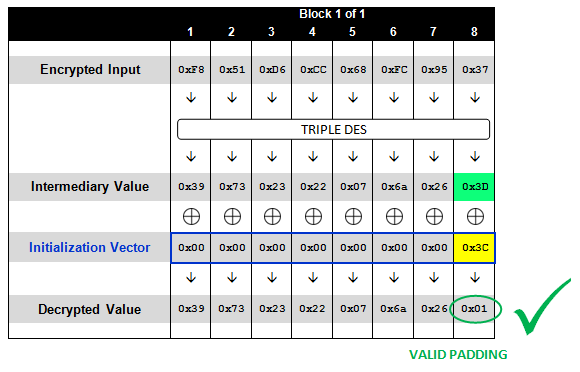
在这个情况下,我们便可以推断出中间值(Intermediary Value)的最后一个字节,因为我们知道它和0x3C异或后的结果为0x01,于是:
因为 [Intermediary Byte] ^ 0×3C == 0×01, 得到 [Intermediary Byte] == 0×3C ^ 0×01, 所以 [Intermediary Byte] == 0×3D
现在我们可以更进一步。我们已经知道了中间值的最后一个字节,于是我们可以推断出解密后的值是多少。您可以回忆一下,在解密的过程中,中间值的每个字节都会与密文中的前一个数据块(对于第一个数据块来说便是IV)的对应字节进行异或操作,于是我们使用之前示例中原来的IV中的最后一个字节(0x0F),与中间值异或一下便可以得到明文。不出意料,我们会得到0x32,这表示数字“2”(明文中第一个数据块的最后一个字节)。
我们现在已经破解了示例数据块中的第8个字节,是时候关注第7个字节了。在破解第8个字节时,我们使用暴力枚举IV,让解密后的最后一个字节成为0x01(合法填充)。在破解第7个字节的时候,我们要做的事情也差不多,不过此时要求第7个字节与第8个字节都为0x02(再重复一遍,这表示合法的填充)。我们已经知道,中间值的最后一个字节是0x3D,因此我们可以将IV中的第8个字节设为0x3F(这会产生0x02)并暴力枚举IV的第七个字节(从0x00开始,直至0xFF)。
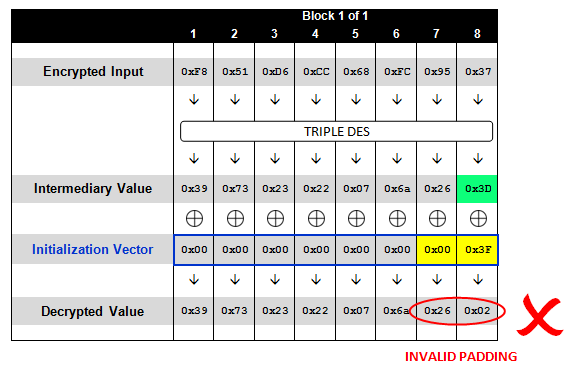
我们再次遭遇填充异常,直至遇上某个值,它使得解密后的第7个字节成为0x02(正确填充),此时IV中的字节为0x24:

使用这种技巧,我们可以从后往前破解中间值里的每个字节,最终得到解密后的值(尽管每次一个字节)。下图展示了完全破解后的IV值,此时整个数据块都为填充值(0x08):

使用PadBuster进行解密
(译注:这段内容为PadBuster的使用指南,在此略过,如果您对这部分内容感兴趣可以阅读原文。)
加密任意的值
我们已经知道如何利用Padding Oracle和PadBuster来依次破解每个加密的数据块。现在,我们就来观察下如何使用同样的漏洞来加密任意数据。
可能您已经发现,一旦我们可以推断出密文数据块的中间值,我们便能通过操作IV的值来完全控制解密所得到的结果。例如,在前面的示例中,如果想要将密文中第一个数据块解密为“TEST”这个值,您可以计算出它所需要的IV值,只要将目标明文与中间值进行异或操作即可。因此,只要您将字符串“TEST”(自然,还包括四个0x04字节作为填充)与中间值异或之后,便可以得到最终的IV,即0×6D,0×36,0×70,0×76,0×03,0×6E,0×22,0×39:
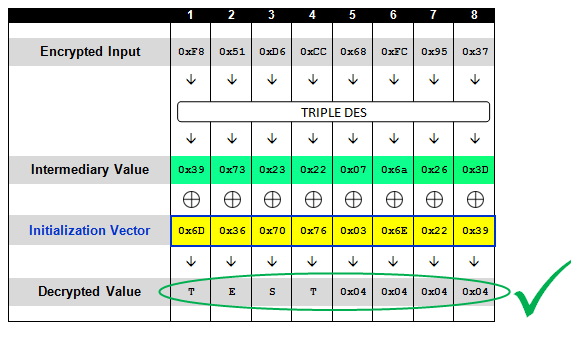
这种做法对于单个数据块来说自然没有问题,但如果我们想要用它来生成长度超过一个数据块的值又该怎么办呢?我们来看一个简单通俗的实际案例。这次我们要生成一个加密的字符串“ENCRYPT TEST”而不仅仅是“TEST”。第一步,还是将文本分拆成数据块,并补上必须的填充字节,如下图:

在构造超过一个数据块的值时,我们实际上是从最后一个数据块开始,向前依次生成所需的密文。在这里,最后的数据块与之前的相同,因此我们已经知道以下的IV和密文能够生成字符串“TEST”:
Request: http://sampleapp/home.jsp?UID=6D367076036E2239F851D6CC68FC9537
接下来,我们需要弄明白中间值6D367076036E2239在作为密文,而不是IV传递至应用程序时会被如何解密。在这里只要使用与破解过程相同的技巧就行了,我们把它作为密文传递给应用程序,并从全部为NULL的IV开始进行暴力破解:
Request: http://sampleapp/home.jsp?UID=00000000000000006D367076036E2239
一旦我们通过暴力破解得到中间值之后,IV便可以用来生成我们想要的任意值。新的IV可以被放在前一个示例的前面,这样便可以得到一个符合我们要求的,包含两个数据块的密文了。这个过程可以不断重复,这样便能生成任意长度的数据了。
使用PadBuster加密任意的值
(译注:这段内容为PadBuster的使用指南,在此略过,如果您对这部分内容感兴趣可以阅读原文。)



















翻译真费时,还总是翻不好……