你的字典里有多少元素?
2014-07-12 23:42 by 老赵, 23760 visits“字典”或者说“哈希表”大家都会用,这真是一个好东西,只要创建了之后就可以不断的丢东西进去,添加删除都是O(1)操作,那叫一个快字了得。不过这里我要再次引用Alan Perlis的名言:“Lisp programmers know the value of everything but the cost of nothing.”,目的是想提醒做事“不要忘记背后的代价”。
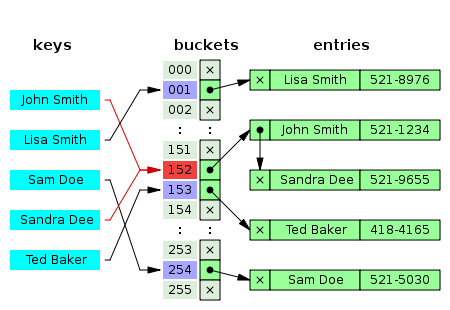
上图引自Wikipedia中“Hash table”条目,描述了最常用的“哈希表”实现方式之一,也是.NET中Dictionary<TKey, TValue>所采用的做法。那么就以.NET中的Dictionary实现来举例,它的代价是什么呢?这里的代价主要是其内存开销。
创建Dictionary对象时我们可以传入一个“容量”值,但这并不是它会使用的实际容量。Dictionary内部会找到“不小于该值的最小质数”来作为它使用的实际容量,最小是3。这么做的目的是减少碰撞几率,因为从哈希值定位buckets时会用到取模操作。得到实际容量之后,就会它用来创建int[] buckets和Entry[] entries两个数组,用来实现间接索引(即buckets中保存的其实是entries数组的下标,具体可以参考Reference Source中的实现代码)。
请注意,这个实际容量也是下次rehash之前可以保存的最大元素个数。因此,假如你预计会要保存N个元素,那么就把N传入构造函数吧,这可以避免一次又一次无谓的rehash操作。
因此,即便你只创建了一个空字典,它至少也创建了两个长度为3的数组,再加上其他杂七杂八的字段,一个字典至少也占用了48个字节——还记得“赵人希”公众账号上的第一篇文章《.NET程序性能的基本要领》吗?
事实上,假如是一次初始化之后需要进行多次查找(很常见的模式),也完全可以尝试排序后使用二分查找。甚至在元素数量很少的时候,使用List<KeyValuePair<TKey, TValue>>保存对象,而在需要读写的时候进行线性查找,效率也不会差。尽管这里的时间复杂度会是O(log(N))甚至O(N),但对于实际开发来说,算法除了“时间复杂度”还有“常数”的因素在里面。使用节省内存的实现方式,更可能会影响到GC的效率,这也是托管程序性能重要方面。
尽管如此,但这样的“问题”还是会到处出现。例如《基本要领》里面提到,他们在对Visual Studio和新编译器进行Profiling时,发现有大量的字典只保存了一个元素——甚至是空的。
上周我们在做Profiling时,也发现程序里一个被密集调用的算法使用了字典保持临时状态,但是在绝大部分情况里,这个字典里面只有5到6个元素,此时使用字典就有些得不偿失了。事实上,那个算法在绝大部分情况下,字典里的元素数量都是可以预知的,只有极少数情况下会超出。因此,算法可以修改为:预先获得元素数量,假如小于一个阈值,则使用普通的数组来保存元素,需要时进行线性查找。虽然这个算法还有更激进的优化手段(性能热点怎么优化都不过分),但现在这种则是最容易,也最安全的做法。
而在.NET框架里也用到了类似的实践。例如为了解决之前也在“赵人希”上提到过的死锁问题,我看了PropertyChangedEventManager类的实现,其中便用到了HybridDictionary类,内部会根据元素数量来切换使用ListDictionary或哈希表来保存数据。
最后再推荐一篇文章吧:《常用数据结构及复杂度》,里面以.NET里的实现为基础,介绍了常用容器各操作的特征。这东西对于一个合格的程序员来说必须是烂熟于心的。其实这东西也完全不用去背,因为这些基础数据结构和算法实在是太容易理解了,几乎只要知道它是怎样一种结构,各特征都可以很快推断出来。
之前我在微博上抱怨过遇到如何如何不靠谱的面试者,连基本的List<T>是怎么存放元素的都搞不清是怎么一回事,居然还有人说这是在考“背诵”,这些细节不重要云云。对此我只想说:既然你就这点追求,那就一辈子老老实实写那些土鳖程序吧,呵呵呵。


























































你好久没有写文章了啊,关注了足足有半年了。