数组排序方法的性能比较(4):LINQ方式的Array排序
2010-01-28 00:06 by 老赵, 7090 visits经过前两篇文章的分析,我们已经了解了Array.Sort<T>与LINQ排序两种实现方式的差别:前者直接比较两个元素的大小,而后者先选出每个元素的“排序依据”再进行比较。因此,虽然后者需要相对较多的“周边工作”,但由于每次比较时都可以仅仅使用高效的基础类型(如int),因此从整体来看,两者的性能高低难以辨别。不过,既然我们已经了解LINQ排序“高效”的原因,又能否将其利用在数组排序上呢?程序是人写的,此类问题大都有肯定的答案。那么我们现在就来实现一下。
API设计
关于这个问题,我设想过几种API使用与设计方式。例如,我起初想使用“标准”的扩展方法:
Person[] people = null; people .OrderBy(p => p.Age) // 指定主要排序规则 .OrderBy(p => p.ID, true /* decending */) // 指定次要排序规则 .Sort(); // 排序
在这样的API中,前两个OrderBy方法用于“收集排序条件”,而在最后的Sort方法中才对数组进行排序。这个API在使用上问题不大,但是在实现上却有两个缺点。首先,对于数组来说,已经有定义在其上的OrderBy方法,新的扩展方法与类库重名,难道要我换个名字嘛?我讨厌动这脑筋;其次,如果说第一个OrderBy方法是定义在数组上的扩展方法,那么第二个OrderBy方法也是数组的扩展方法吗?
其实不然。既然我们要“收集”排序规则,因此必然需要使用一个对象进行保存——就叫做OrderCriteria吧。那么第一个OrderBy方法便返回这样一个OrderCriteria对象,而第二个OrderBy则是定义在OrderCriteria类上的。那么,我们是不是需要为数组和OrderCriteria类各实现“一整套”的OrderBy方法呢?这实在是一件麻烦的事情啊。
于是,我又想到了这样的接口:
new ArraySorter<Person>(people) .OrderBy(p => Age) .OrderBy(p => p.ID, true) .Sort();
这样做的话,我们只要定义一个ArraySorter类型,再提供一套OrderBy方法即可。这种做法不仅仅是省力,“统一”的排序入口还有另一个好处,因为我们可以实现这样的逻辑:
var sorter = new ArraySorter<Person>(people); if (shouldOrderByAge) { sorter.OrderBy(p => p.Age); } if (shouldOrderById) { sorter.OrderBy(p => p.ID); } sorter.Sort();
不过这个接口还是有个缺点:我们无法复用排序规则。例如,如果我们需要为两个类型相同的数组进行规则相同的排序,又该怎么办呢?因此,我打算把接口改为这种:
var sorter = new ArraySorter<Person>(); if (shouldOrderByAge) { sorter.OrderBy(p => p.Age); } if (shouldOrderById) { sorter.OrderBy(p => p.ID); } sorter.Sort(people); sorter.Sort(people2);
由此,“排序器”负责“收集”排序规则,然后可以为多个数组进行排序,似乎颇为理想。
下标比较器(IndexComparer)
那么,我们的类库该如何设计?这里先要明确几个需求:
- 对于每个排序规则,都要先选择排序字段,再进行排序(这是我们写这个类库的意义)。
- 排序可以指定多个排序规则,排序规则之间有优先顺序。
- 不同的排序规则,其使用的字段、类型、比较器、顺序都可能有所不同。
请注意第三个需求,由于我们追求灵活性,因此排序的规则是不确定的。因此,不同的规则之间唯一可以统一的便是“数组下标”。我们在把握住这个“相同点”的基础上,定义这样一个比较器类型:
internal class IndexComparer<TKey> : IComparer<int> { public IComparer<int> NextIndexComparer; private TKey[] m_keyArray; private IComparer<TKey> m_keyComparer; private bool m_decesnding; public IndexComparer(TKey[] keyArray, IComparer<TKey> keyComparer, bool decesnding) { this.m_keyArray = keyArray; this.m_keyComparer = keyComparer ?? Comparer<TKey>.Default; this.m_decesnding = decesnding; } public int Compare(int indexX, int indexY) { var keyX = this.m_keyArray[indexX]; var keyY = this.m_keyArray[indexY]; var result = this.m_keyComparer.Compare(keyX, keyY); if (result == 0) { return this.NextIndexComparer == null ? 0 : this.NextIndexComparer.Compare(indexX, indexY); } else { return this.m_decesnding ? -result : result; } } }
IndexComparer实现了IComparer<int>接口,它的比较内容不是排序的元素,而是“数组下标”。构造一个IndexComparer类型需要提供“排序字段”的数组keyArray,比较器keyComparer,及排序顺序。Compare方法接受的是数组的两个下标,返回值则表示输入的两个下标的先后顺序。因此,IndexComparer对象会从keyArray中两个排序字段的值,并返回比较结果。
值得注意的是,每个IndexComparer都会保存另一个NextIndexComparer引用,它可能为null,或指向另一个IndexComparer对象。因此,多个IndexComparer实际上组成的是一个“比较器链”,而Compare方法在调用时,如果发现当前的key相同,那么便会尝试使用下一个IndexComparer来比较输入的“数组下标”——这里其实是一个职责链模式应用,恰好满足我们对排序条件的优先顺序。
排序条件(OrderCriteria)
那么,由谁来构造IndexComparer链呢?自然是由“排序条件”来构造了:
internal abstract class OrderCriteria<TElement> { public abstract IComparer<int> CreateComparer(TElement[] array); public OrderCriteria<TElement> NextCriteria; }
OrderCriteria<TElement>类是排序条件的基类,表示TElement数组的“一个”排序条件。和IndexComparer相同,每个OrderCriteria对象都维护着表示下一个排序条件的对象。OrderCriteria<TElement>有一个抽象方法,用于创建一个比较器——不,确切地说,应该是一个“比较器链”才对:
internal class OrderCriteria<TElement, TKey> : OrderCriteria<TElement> { private IComparer<TKey> m_keyComparer; private Func<TElement, TKey> m_keySelector; private bool m_descending; public OrderCriteria( Func<TElement, TKey> keySelector, IComparer<TKey> keyComparer, bool decesnding) { this.m_keySelector = keySelector; this.m_keyComparer = keyComparer; this.m_descending = decesnding; } public override IComparer<int> CreateComparer(TElement[] array) { var keyArray = new TKey[array.Length]; for (int i = 0; i < array.Length; i++) { keyArray[i] = this.m_keySelector(array[i]); } var comparer = new IndexComparer<TKey>(keyArray, this.m_keyComparer, this.m_descending); if (this.NextCriteria != null) { comparer.NextIndexComparer = this.NextCriteria.CreateComparer(array); } return comparer; } }
OrderCriteria<TElement, TKey>表示“按照TKey类型来排序TElement数组”的排序规则。在CreateComparer方法中,它会使用keySelector计算出一个TKey数组作为排序依据,再用其构造一个IndexComparer对象。如果NextCriteria字段不为空,那么便以此指定当前IndexComparer的下一个比较器对象。最终返回的,自然就是一个完整的比较器链了。
数组排序器(ArraySorter)
终于涉及到面向用户的类型了。其实这个类型非常简单,只有一套OrderBy方法和一个Sort方法。我们首先来关注最核心的OrderBy方法(以及一个可能的重载):
public class ArraySorter<TElement> { private OrderCriteria<TElement> m_headCriteria; private OrderCriteria<TElement> m_tailCriteria; public ArraySorter<TElement> OrderBy<TKey>(Func<TElement, TKey> keySelector) { return this.OrderBy(keySelector, null, false); } public ArraySorter<TElement> OrderBy<TKey>( Func<TElement, TKey> keySelector, IComparer<TKey> keyComparer, bool descending) { var newCriteria = new OrderCriteria<TElement, TKey>( keySelector, keyComparer, descending); if (this.m_headCriteria == null) { this.m_headCriteria = this.m_tailCriteria = newCriteria; } else { this.m_tailCriteria.NextCriteria = newCriteria; this.m_tailCriteria = newCriteria; } return this; } ... }
每次调用OrderBy方法时,都会为ArraySorter内部的OrderCriteria单向链表增加一个元素。因此,整套类库的结构示意图大约是这样的:
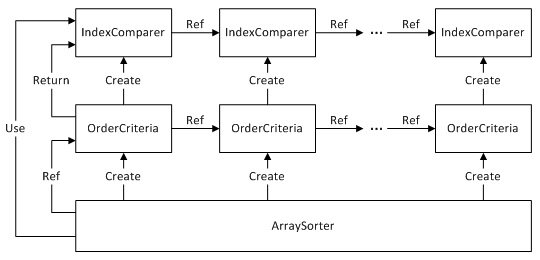
至于Sort方法,那就更加简单了:
public void Sort(TElement[] array) { if (this.m_headCriteria == null) return; var indexComparer = this.m_headCriteria.CreateComparer(array); var indexArray = new int[array.Length]; for (int i = 0; i < array.Length; i++) indexArray[i] = i; Array.Sort(indexArray, array, indexComparer); }
如果没有指定任何排序条件自然直接返回,否则创建一个indexComparer链作为比较器。那么我们又是如何排序数组的呢?那就要谢过.NET类库中丰富的功能了。我们使用的是这个重载:
static void Sort<TKey, TElement>(TKey[] keys, TElement[] items, IComparer<TKey> comparer);
这个重载的功能是将keys数组作为排序依据,但同时也会根据对应的下标排序items数组——这不正是我们的需求吗?
性能测试
哈,写完了,测试一下性能吧。由于我们目前的实现是参考了LINQ排序,因此我们这里直接和它进行比较吧:
public class Person { public int ID; }
static void Main(string[] args) { var random = new Random(DateTime.Now.Millisecond); var array = Enumerable.Repeat(0, 1000 * 500) .Select(_ => new Person { ID = random.Next() }).ToArray(); CodeTimer.Initialize(); CodeTimer.Time("SortWithLinq", 10, () => SortWithLinq(CloneArray(array))); CodeTimer.Time("SortWithArraySorter", 10, () => SortWithArraySorter(CloneArray(array))); Console.ReadLine(); } static void SortWithLinq(Person[] people) { var sorted = (from i in people orderby i.ID select i).ToList(); } static void SortWithArraySorter(Person[] people) { new ArraySorter<Person>().OrderBy(p => p.ID).Sort(people); } static T[] CloneArray<T>(T[] source) { var dest = new T[source.Length]; Array.Copy(source, dest, source.Length); return dest; }
结果如何?
SortWithLinq
Time Elapsed: 3,861ms
CPU Cycles: 8,174,533,048
Gen 0: 7
Gen 1: 7
Gen 2: 7
SortWithArraySorter
Time Elapsed: 4,791ms
CPU Cycles: 10,353,862,211
Gen 0: 5
Gen 1: 4
Gen 2: 4
什么?性能反而变差了!
经过仔细和分析和比对之后,我可以确定我们的做法和LINQ排序可谓如出一辙。事实上,我们的做法就是参考了LINQ排序的实现方式(如“职责链”),在保留其优点的前提下进行一定简化的结果。那么性能究竟差在什么地方呢?
性能优化
似乎唯一可能产生性能差距的地方只有排序算法了。LINQ排序使用的是重写的排序算法,而我们则直接调用了Array.Sort方法的某个重载,难道问题出在这里?为此,我找到了Array.Sort方法的根源,其中有这样的代码:
namespace System.Collections.Generic { internal class ArraySortHelper<TKey, TValue> { internal static void QuickSort( TKey[] keys, TValue[] values, int left, int right, IComparer<TKey> comparer) { ... if (values != null) { TValue local3 = values[a]; values[a] = values[b]; values[b] = local3; } ... } } }
在QuickSort方法中,如果传入了values数组,则会在交换keys数组中元素的同时,一并交换values对应下标的元素。还记得我们我们之前对比较各种数组复制的性能的试验吗?从结果中我们得知,各种复制方式中最慢的便是根据下标一一复制。因为对于引用类型来说,为了避免GC造成影响,在每次进行引用复制时都会动用Write Barrier,性能降低再所难免。
于是,我们尝试着把ArraySorter的Sort方法修改成这样吧:
public void Sort(TElement[] array) { if (this.m_headCriteria == null) return; var indexComparer = this.m_headCriteria.CreateComparer(array); var indexArray = new int[array.Length]; for (int i = 0; i < array.Length; i++) indexArray[i] = i; // Array.Sort(indexArray, array, indexComparer); Array.Sort(indexArray, indexComparer); var arrayCopy = new TElement[array.Length]; Array.Copy(array, arrayCopy, array.Length); for (int i = 0; i < array.Length; i++) { array[i] = arrayCopy[indexArray[i]]; } }
现在,我们来直接排序indexArray数组,并准备一个array数组的副本arrayCopy,最后再根据indexArray中保存的下标,把arrayCopy里的内容复制回array中去。那么再次试验一下吧:
SortWithLinq
Time Elapsed: 3,756ms
CPU Cycles: 7,856,900,073
Gen 0: 8
Gen 1: 8
Gen 2: 8
SortWithArraySorter
Time Elapsed: 3,672ms
CPU Cycles: 7,833,900,349
Gen 0: 5
Gen 1: 4
Gen 2: 4
虽然领先不多(几乎还在误差范围内),但至少不比前者慢了(这个结果很稳定,您可以亲自进行多次试验)。您可能会想,我们最后再为array数组赋值的时候又没有使用Array.Copy,为什么会有性能提升呢?这是因为,如果直接使用Array.Sort(keys, items)进行排序的话,对items数组的读写(交换元素)次数会高出许多。因此在作了这样的修改时候,目前的性能和原来相比会有不小的提升。
总结
啊哈,那么和原来的Array.Sort方法相比,我们编写的ArraySorter又会有哪些好处呢?关于这个问题,我们下次再来讨论吧,您也可以自己先进行一些测试。
当然,现在的ArraySorter还需要一些改进。例如,它还没有对输入参数进行校验,重载也不足够。另外,对于引用类型来说,我们最后的优化是有效果的,那么对于值类型或其他类型来说又如何呢?我还没有进行试验,这就交给您来发现了。
本文代码:http://gist.github.com/287857
相关文章
- 数组排序方法的性能比较(1):注意事项及试验
- 数组排序方法的性能比较(2):Array.Sort<T>实现分析
- 数组排序方法的性能比较(3):LINQ排序实现分析
- 数组排序方法的性能比较(4):LINQ方式的Array排序
- 数组排序方法的性能比较(5):对象大小与排序性能







抢个板凳..慢慢看