是否会成为问题——Linq to Sql的执行可能无法复用查询计划
2007-11-21 08:43 by 老赵, 5411 visits查询计划
Sql Server在执行一条查询语句之前都对对它进行“编译”并生成“查询计划”,查询计划告诉Sql Server的查询引擎应该用什么方式进行工作。Sql Server会根据当前它可以收集到的各种信息(例如内存大小,索引的统计等等)把一条查询语句编译成它认为“最优”的查询计划。很显然,得到这样一个查询计划需要消耗CPU资源,而大部分的查询语句每次经过编译所得到的查询计划往往是相同的,因此除非指定了RECOMPILE选项,Sql Server在执行查询语句时,会对查询计划进行缓存——也就是说,如果是相同的查询语句,Sql Server只会对它进行一次编译操作,然后在每次执行时对查询计划进行复用。查询计划如果无法复用,则会在相当程度上降低数据库性能——因为过多的CPU被消耗在查询语句的编译上。各种提及数据库查询优化的资料上大都会提到这一点,我们往往通过查看性能计数器的某些统计,或者Sql Server系统表中的一些记录,就可以判定您的数据库应用是否出现了这个问题。
对于存储过程来说,复用查询计划是轻而易举的。不过对于那些喜欢在程序代码中拼接Sql字符串的朋友来说,日子就有些不好过了。Sql Server是根据您传入的Sql语句来缓存查询计划的,如果您“强行”拼接了Sql字符串并交给Sql Server执行,那么查询计划被复用的可能性微乎其微。因此,我们绝对应该杜绝拼接字符串的行为,因为这不仅仅造成了传统的Sql注入!而那些习惯相对较好的朋友,则会使用带参数的Sql语句,在交给Sql Server执行时就可能复用查询计划。因为和调用存储过程相比,发送带参数的Sql语句只是将使用了sp_executesql命令而已,每次执行的查询语句还是相同的。
问题何在?
对于复用查询计划的问题,在上文中我说了这么一句话:“……使用带参数的Sql语句,在交给Sql Server执行时就可能复用查询计划……”。我为什么要说“可能”?因为即时使用带参数的Sql语句,在某些情况下我们还是无法对查询计划进行复用。这是怎么一回事儿呢?我们还是直接从Linq to Sql来产生Sql语句,然后观察Sql Server的行为吧。
请看以下的代码(示例所操作的数据表与《在Linq to Sql中管理并发更新时的冲突(2):引发更新冲突》一文相同):
LinqToSqlDemoDataContext dataContext = new LinqToSqlDemoDataContext();
dataContext.Log = Console.Out;
Video video1 = dataContext.Videos.SingleOrDefault(
v => v.Introduction == "Hello");
Video video2 = dataContext.Videos.SingleOrDefault(
v => v.Introduction == "Hello World");
Console.ReadLine();
还是查看输出:
SELECT [t0].[VideoID], [t0].[Introduction], [t0].[SiteID]
FROM [dbo].[Video] AS [t0]
WHERE [t0].[Introduction] = @p0
-- @p0: Input NVarChar (Size = 5; Prec = 0; Scale = 0) [Hello]
-- Context: SqlProvider(Sql2005) Model: AttributedMetaModel Build: 3.5.21004.1
SELECT [t0].[VideoID], [t0].[Introduction], [t0].[SiteID]
FROM [dbo].[Video] AS [t0]
WHERE [t0].[Introduction] = @p0
-- @p0: Input NVarChar (Size = 11; Prec = 0; Scale = 0) [Hello World]
-- Context: SqlProvider(Sql2005) Model: AttributedMetaModel Build: 3.5.21004.1
两局Sql语句完全相同,按我们刚才的说法,Sql Server应该缓存了查询计划。但是我们通过查看sys.syscacheobjects的相关数据可以看出,事情并非如同我们想象的那样:
SELECT cacheobjtype, sql FROM sys.syscacheobjects;
DBCC freeproccache;
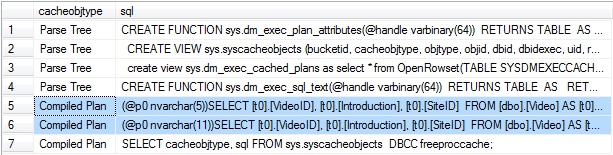
请注意上图中被选中的两条记录,它表明了Sql Server并没有缓存执行计划。
为什么?这两次执行究竟有什么区别?通过Linq to Sql很容易看出,两次执行所用到的参数不同。更进一步,如果对比Linq to Sql输出的缓存以及sys.syscacheobjects视图中的记录,就会发现:其实仅仅是参数的尺寸不同。
没错,就是这个原因。在使用ADO.NET时,如果SqlParameter的Type是nvarchar,并且没有指定Size属性,则可能就会因为具体参数的尺寸不同而造成查询计划无法复用的结果。这一点,很多人都忽视了。
优化方案
在使用ADO.NET进行开发时,该问题其实很容易解决。我们只要指定SqlParameter的Size属性即可。由于每次指定了一个固定的参数尺寸,Sql Server就能够复用查询计划了。
不过我们现在在使用Linq to Sql,又该怎么做呢?嗯,我们可以为XXXXDataContext重写(override)SubmitChanges方法,在其中获得需要执行的SqlCommand对象(具体方法请参考《在Linq to Sql中管理并发更新时的冲突(1):预备知识》一文),获得其中的SqlParameter参数,并设定它们的Size属性。我们可以使用Custom Attribute来标注应该为哪个属性设置什么样的Size,如果再结合AOP,哈哈……
等等,先别想那么远。即使得到了SqlCommand对象,它所生成的Sql语句是以@p0、@p1作为参数名,您知道该修改哪个SqlParameter对象吗?再者,SubmitChanges方法只是提交我们做出的修改,但是在一般的系统中,查询操作的次数和性能消耗大大超过修改操作,而重写了SubmitChangeds方法又不能影响我们的优化操作……
因此,我想在这里说的是:这个问题我们没法进行优化。
不过我们还是幸运的,因为我根据我的经验,似乎在查询条件中使用长度不等的字符串作为参数的情况并不多见。不是么?

![gakaki[未注册用户]](http://www.gravatar.com/avatar/d6f82e1c0b4bd7b9828e796186c7938b.jpg?d=http%3a%2f%2fblog.zhaojie.me%2fimages%2fprofile.gif&s=50)




so LINQis worse than store procedure TOO? it can not be compile in sqlserver